DAPO
https://arxiv.org/abs/2503.14476
This is mostly generate by Gemini 3-pro
1. Introduction (引言):为何复现 R1 这么难?
这部分主要交代了背景和动机。
- 现状: Test-time scaling(如 OpenAI o1, DeepSeek R1)通过强化学习激发了 LLM 的推理能力(Long CoT)。
- 问题: 关键的 RL 细节被隐藏了。社区尝试用朴素的 GRPO 复现,结果很差。作者自己在 Qwen2.5-32B 上跑朴素 GRPO,AIME 只有 30 分,而 DeepSeek 报告是 47 分。
- 分析: 朴素 GRPO 存在三大问题:
- Entropy Collapse(熵坍缩): 模型过早收敛,失去探索能力
- Reward Noise(奖励噪声): 主要是截断(Truncation)导致的。
- Training Instability(训练不稳定)。
- 贡献: 提出了 DAPO 算法,并在
verl框架上开源了代码和数据。结果是 50 分,且训练步数只需 DeepSeek 的 50%
2. Preliminary (预备知识):重温 PPO 与 GRPO
2.1 PPO: 经典回顾。核心是 Clip 机制限制策略更新幅度。
2.2 GRPO (Group Relative Policy Optimization):
- 核心: 去掉了 Value Function (Critic),节省显存。
- 优势计算: 通过采样一组 $G$ 个输出来计算 Group 内部的相对优势: $$\hat{A}{i,t}=\frac{r{i}-mean({R_{i}}{i=1}^{G})}{std({R{i}}_{i=1}^{G})}$$
- 关键伏笔: 传统的 GRPO 是 Sample-level 的 Loss 计算(先对每个样本内的 token loss 求平均,再对样本求平均)7。这一点在后面会被 DAPO 批判。
2.3 Removing KL Divergence (去掉了 KL 散度):
- Insight: 在 RLHF 中,我们需要 KL 来防止模型偏离“人话”。但在 Long-CoT 推理任务中,模型分布必须显著偏离 SFT 模型(因为要产生新的推理模式),所以作者去掉了 KL 惩罚项。
2.4 Rule-based Reward: 只看最终答案是否正确(1 或 -1),不搞复杂的 Process Reward Model,避免 Reward Hacking。
3. DAPO (核心方法):四大“魔改”技术
这是论文最精华的部分,详细解释了如何解决 Section 1 提出的问题。

compare to GRPO
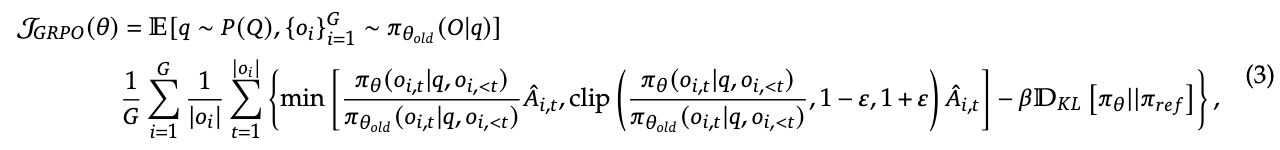
3.1 Raise the Ceiling: Clip-Higher (解耦裁剪)
- 问题: 实验发现 Policy Entropy 掉得太快(熵坍缩),模型不仅不探索,而且不同采样的输出变得一模一样。
熵: $H(\pi) = -\sum p_i \log p_i$, 在信息论中,熵衡量的是不确定性或混乱程度。在 RL 里的 Policy 上,熵代表了模型输出的多样性(探索能力)。
- 原因分析: PPO 的 Clip 机制通常是 $[1-\epsilon, 1+\epsilon]$(默认 0.2)。
- 对于高概率 Token(Exploitation),比如 $p=0.9$,上限 $1.2$ 对它没啥限制。
- 理论上新概率 $p_{new}$ 可以达到 $0.9 \times 1.2 = 1.08$。
- 对于低概率 Token(Exploration),比如 $p=0.01$,上限变成 $0.012$。
这意味着低概率的探索性 Token 很难通过梯度更新被“提拔”上来。
- 对于高概率 Token(Exploitation),比如 $p=0.9$,上限 $1.2$ 对它没啥限制。
PPO 的 Clip 机制对低概率 Token 的“提拔”限制太死,导致那些一开始概率低的“潜力股”很难翻身,模型最终只能选择一开始概率就高的“平庸股”,导致熵坍缩
- DAPO 方案: 解耦 Clip 范围。
- 保持 $\epsilon_{low} = 0.2$(防止概率降到 0 导致采样空间坍缩)。
- 提高 $\epsilon_{high} = 0.28$。
- 效果: 允许低概率 Token 有更大的上升空间,从而维持了 Exploration。
3.2 The More the Merrier: Dynamic Sampling (动态采样)
问题: 随着训练进行,很多 Prompt 的准确率变成了 100%(全对)或 0%(全错)。
- 在 GRPO 中,如果一组采样 ${o_i}$ 的奖励全是一样的(全 1 或全 -1),那么 Advantage 全是 0。
- 这意味着这些样本对梯度没有任何贡献,导致 batch 内有效样本数减少,梯度方差变大,训练效率低。
DAPO 方案: Buffer 机制 + 过滤。
- 在采样阶段,如果是全对或全错的 prompt,直接扔掉。
- 不断采样,直到填满一个 Batch 的有效样本(Advantage 不为 0 的样本)。
效果: 虽然采样时间变长了,但训练步数大幅减少,总收敛时间反而变快了。
3.3 Rebalancing Act: Token-Level Policy Gradient Loss (Token 级损失)
问题: 原版 GRPO 是 Sample-level Averaging。
假设 Response A 长 1000 tokens,Response B 长 100 tokens。在 Sample-level 下,它们对 Loss 的贡献权重是一样的(各占 1/BS)。
这导致长 CoT(往往包含更复杂的推理)中的 token 被“稀释”了。
这也导致模型倾向于生成长而无意义的废话(Gibberish),因为在 Sample-level 下这些废话没有受到足够的惩罚 17。
DAPO 方案: 改为 Token-level Summation。
公式分母变成 $\sum |o_i|$(所有 token 总数),而不是样本数 $G$ 18。
这样,更长的推理链条在梯度更新中拥有更大的权重,且生成废话的 token 会受到更直接的惩罚。
3.4 Hide and Seek: Overlong Reward Shaping (超长截断处理)
问题: 训练都有最大长度限制(如 4096)。如果模型推理正确但没写完被截断了,通常给 -1 分。
- 这会给模型错误的信号:“我推理是对的,为什么惩罚我?” 导致 Reward Noise 19。
DAPO 方案:
Overlong Filtering: 直接 Mask 掉截断样本的 Loss,不学它 20。
Soft Overlong Punishment: 引入一个“软惩罚区间”。如果长度接近最大限制,给予一个随长度增加的负奖励,引导模型学会精简,而不是直接截断 21212121。
4. Experiments (实验)
这部分验证了 DAPO 的有效性。
配置:
- Base Model: Qwen2.5-32B。
- Framework:
verl。 - Data: DAPO-Math-17K (作者自己清洗的数据集,把所有答案转成了整数以便验证)。
主结果 (Ablation Study) : 这一段非常精彩,展示了每个技术加进去后的提升:
- Naive GRPO: 30%
- Overlong Filtering: 36% (解决噪声)
- Clip-Higher: 38% (解决探索)
- Soft Punishment: 41%
- Token-level Loss: 42% (解决稳定性)
- Dynamic Sampling: 50% (解决效率和梯度质量)
- 对比 DeepSeek R1 Zero: 47%。DAPO 胜出。
训练动态分析 (Training Dynamics):
- 长度变化: 长度不是一直涨的,会经历“停滞”甚至“下降”,这很正常 24。
- 涌现现象 (Case Study): 论文展示了一个例子,模型在训练初期不会检查答案,后期涌现出了 “Wait a moment, let’s rethink…” 这种自我反思的行为 25。
5. 总结
DAPO 通过解耦 Clip(促进探索)、动态采样(保证梯度质量)、Token-level Loss(适应长链推理)和合理的截断处理,成功在开源框架下复现并超越了 DeepSeek-R1-Zero 的效果。